Blog
Breaking the ‘Intelligence Ceiling’: How Gruve and Fleak Achieved Tier 3 Threat Detection Fidelity
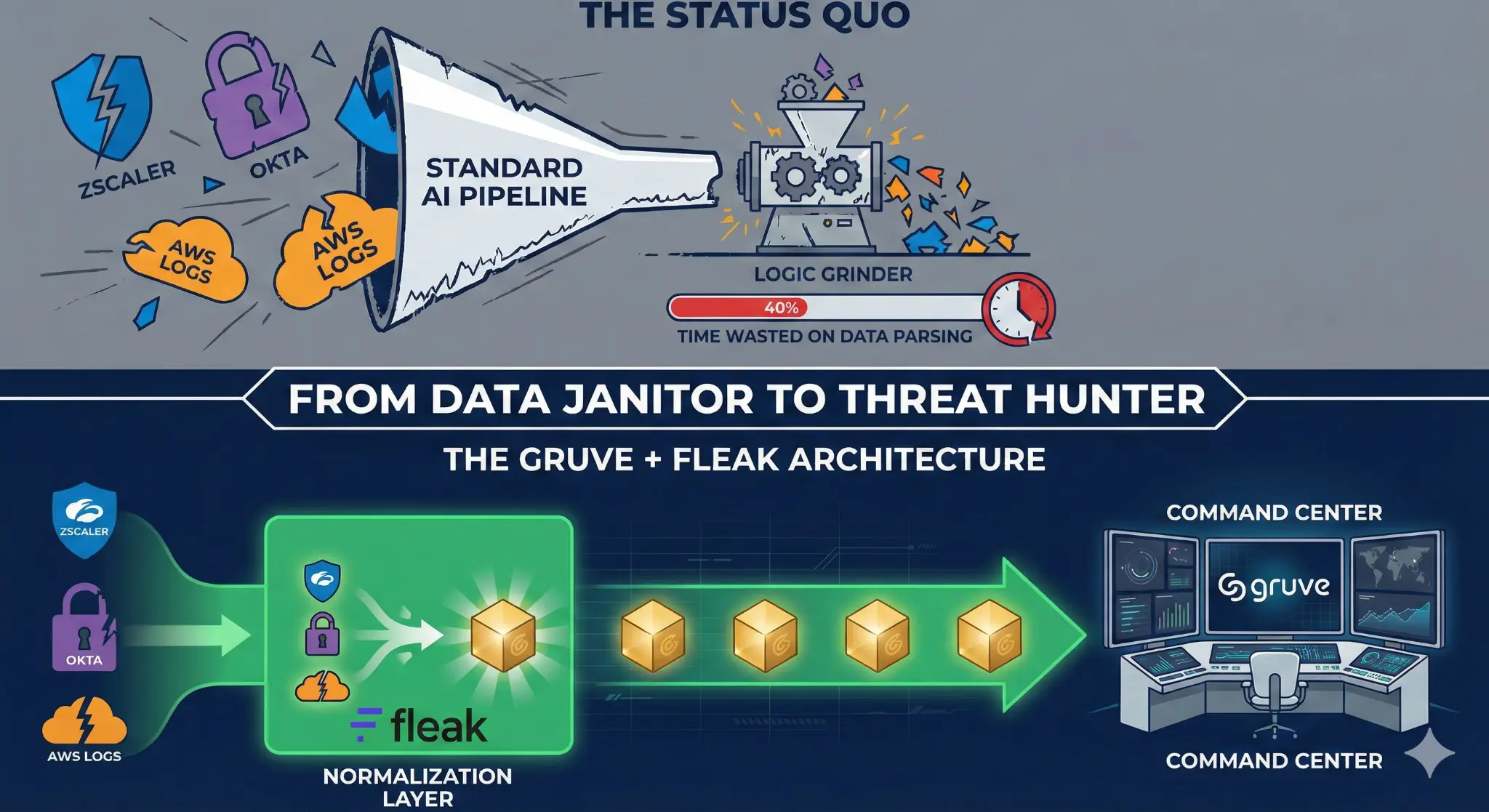
Standard pipelines waste 40% on “logic grinding.” The Gruve + Fleak architecture ends the janitor work. With Fleak’s Normalization Layer, raw logs from Zscaler and Okta become actionable intelligence in the Gruve Command Center.
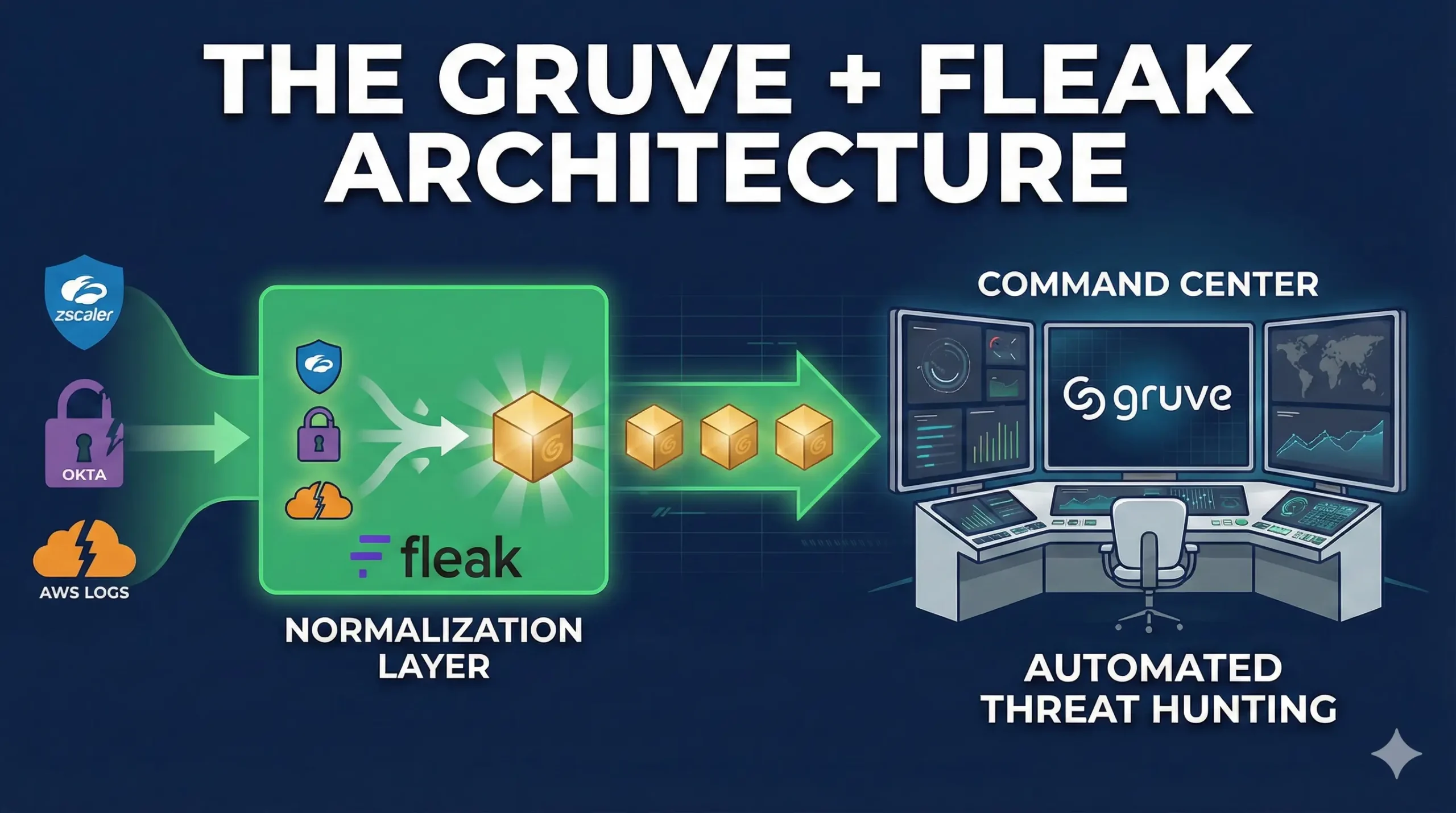
1. The Core Discovery
This report documents a collaborative performance benchmark between Gruve and Fleak.ai, designed to explore the relationship between data architecture and AI-driven security outcomes. We conducted a controlled A/B test to observe how a high-performance UEBA agent—the core of Gruve’s AI SOC—performs when supported by different data pipeline configurations: raw heterogeneous logs vs. Fleak.ai-normalized OCSF data.
The Conclusion: Data normalization is the primary catalyst for maximizing AI reasoning. The test demonstrated that while the Gruve AI-powered SOC engine is highly capable of processing raw logs, feeding it Fleak.ai-normalized OCSF allowed the model to bypass the “parsing phase” and move immediately to “high-fidelity analysis.” This resulted in a shift from standard alert generation to the identification of complex, multi-stage threat patterns—achieving a Tier 3 Hunter performance profile without increasing operational latency or token costs.
2. Test Design & Performance Overview
To ensure scientific validity, the test held all detection variables constant except for the data format. This was not a phased rollout, but a side-by-side comparison of the same dataset.
A. The Constants (Control Variables)
- The Dataset: Identical Zscaler Private Access (ZPA) log set containing hidden attack patterns.
- The AI Engine: The same Large Language Model (LLM) agent part of Gruve’s AI-powered cybersecurity stack was used for both scenarios was used for both scenarios.
- The Prompt: Identical System Prompt. The agent was given the exact same instructions: “You are an enterprise-grade UEBA engine. Analyze logs for behavioral anomalies, deviations, and insider threats. Do not use static IOCs.”
B. The Variable (The Change)
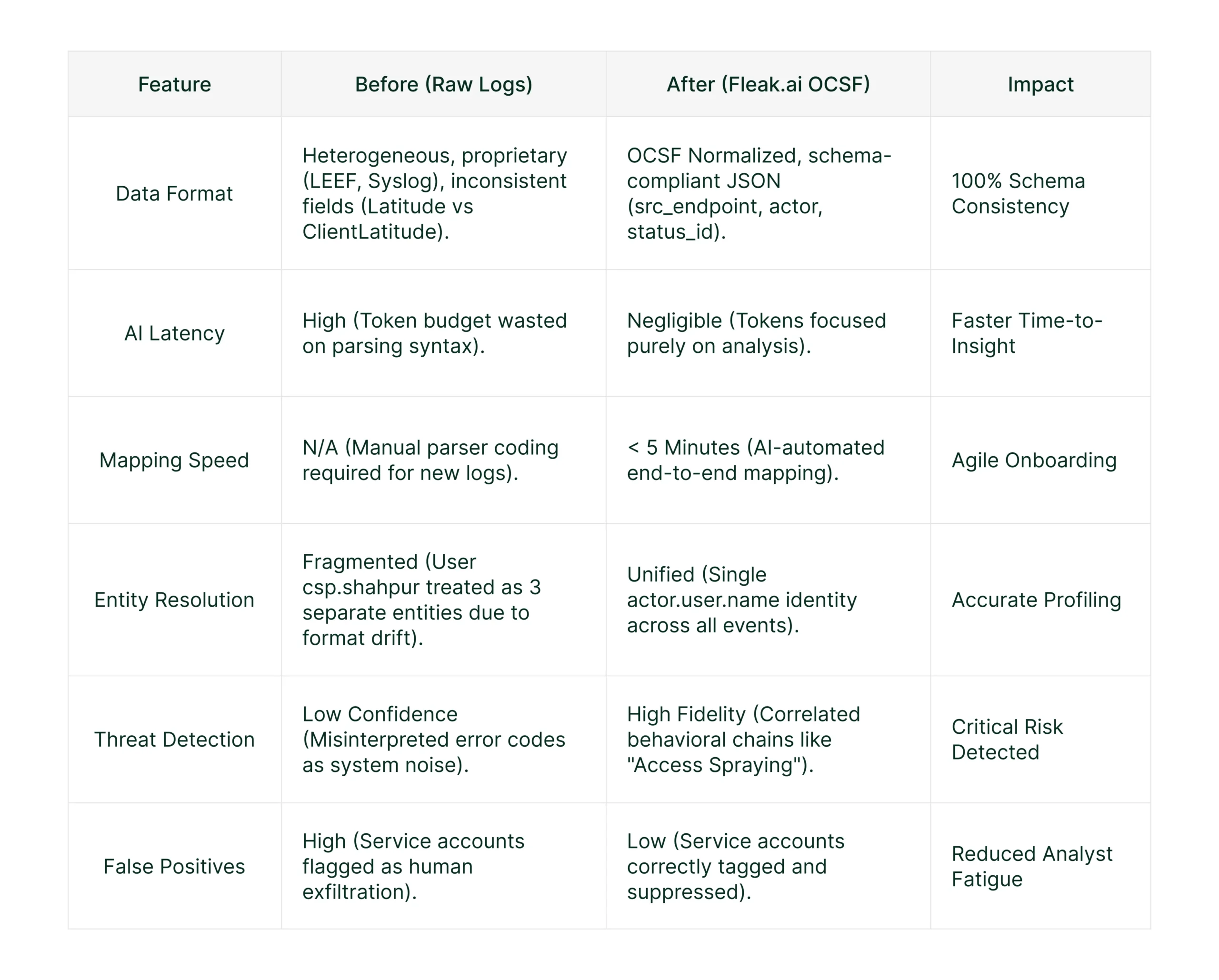
- Scenario A (Baseline): Raw Logs. The AI ingested native, messy logs (mixed formats, inconsistent field names like Latitude vs. ClientLatitude).
- Scenario B (Fleak.ai): OCSF Logs. The AI ingested the same data, normalized and enriched by Fleak.ai into the Open Cybersecurity Schema Framework (OCSF).
Comparative Performance Summary: Raw Logs vs. Fleak.ai OCSF
3. Operational Efficiency & Latency
A key finding is that the performance boost in Scenario B did not come at the cost of detection speed.
- Runtime Latency: Negligible. For existing log types, Fleak.ai’s normalization occurs in-stream with almost no processing overhead, preserving real-time detection capabilities.
- New Log Onboarding: < 5 Minutes. For completely new, unknown event types, Fleak.ai’s AI-native mapping agent generates end-to-end OCSF parsers in under 5 minutes.
- Result: The system achieves structured data clarity at the speed of raw log ingestion.
4. Comparative Detection Results
The specific threat scenarios hidden within the dataset illustrate how the same AI agent interpreted the same events differently based on data format. This builds on the multi-agent threat hunting approach we’ve deployed for enterprise clients, where data quality directly determines hunting depth.

5. Strategic Implications
For a security product company, these results demonstrate that Data Quality is the ceiling for AI performance.
- AI Cost Reduction: By normalizing data before it hits the AI model, you remove the need for the LLM to burn tokens parsing syntax. It focuses 100% of its context window on threat analysis. This directly addresses the alert fatigue and analyst overload challenges we outlined in our piece on how AI is transforming SOC analyst workflows.
- Agility: New data sources can be onboarded in minutes (via Fleak’s AI mapping) rather than weeks of manual parser coding, without breaking downstream detection logic.
- Reliability: Detection logic becomes schema-agnostic. A “Brute Force” prompt works for any identity provider (Okta, Azure AD, Zscaler) because they are all mapped to the same OCSF standard.


